| II. | Relatório Técnico
|
|
1. |
Objetivo |
|
|
Definiçăo de um modelo XML para a base de dados que está sendo criada para a Biblioteca IME. Este modelo deverá ser usado para fazer a carga da nova base de dados, a partir da importaçăo de dados de bases já existentes.
|
|
2. |
Contexto
|
|
|
2.1. |
Modularidade do Sistema de Informatizaçăo |
|
|
|
Este trabalho é um sub-projeto que integra o Projeto de Informatizaçăo da Biblioteca do IME.
O sistema está dividido em módulos, minimizando a dependęncia entre os grupos de desenvolvimento do projeto.
 |
| Estrutura de Dados | Controle de Fluxo
[INFO-FLOW] |
|
|
FIG 2.1.a) Modularidade do Sistema de Informatizaçăo
A definiçăo do modelo XML encaixa-se no Módulo Acervo.
|
|
|
2.2. |
Bases de Dados |
|
|
|
Os dados do Acervo da Biblioteca encontram-se, no momento, em duas bases de dados:
IDBIME (sistema próprio da Biblioteca do IME
Dedalus (Banco de Dados Bibliográficos da USP)
Urge sistematizar o processo de importaçăo de dados das bases existentes para a nova base que está sendo criada.
FIG 2.2.a) Importaçăo de Dados
|
|
3. | XML: eXtensible Markup Language |
|
|
3.1 |
Introduçăo |
|
|
|
XML é uma linguagem de marcaçăo, assim como HTML. Basicamente, o que diferencia estas duas linguagens é que a primeira foi criada para descrever dados, enquanto que a segunda foi criada para exibir dados.
XML permite que o desenvolvedor crie seus próprios marcadores (estruturas rotuladas tag), daí sua flexibilidade.
Há apenas uma primeira linha [ver fig. exemplo 1] que é obrigatória para que o documento seja validado: uma declaraçăo XML que define a versăo XML do documento em questăo.
FIG. 3.1.a) Exemplo 1
|
|
|
3.2 |
Estrutura Básica dos Marcadores |
|
|
|
| 3.2.1 | Elementos |
|
Cada marcador define um elemento, que pode possuir elementos-filhos.
É uma estrutura em árvore: uma raiz com nós-filho.
FIG 3.2.1.a) Exemplo 2
|
| 3.2.2 | Atributos |
|
Elementos podem ter atributos associados a eles: uma informaçăo adicional que năo descreva uma estrutura.
Năo há uma regra que explicite quando um dado é um elemento ou um atributo, mas há desvantagens no uso desse último.
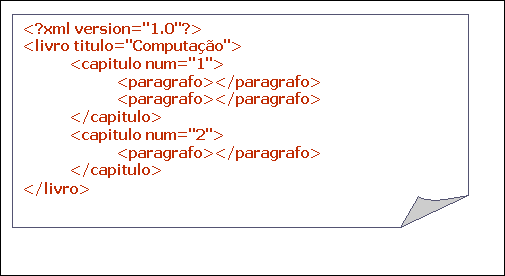
No exemplo abaixo [FIG 3.2.2.a)], título năo deveria ser definido como atributo do elemento livro. Note que título é uma estrutura que pode conter subtítulos. Atributos năo săo expansíveis e nem multi-valorados, e seu uso năo é recomendado em vários casos.
Ainda no exemplo abaixo, o número do capítulo é apenas uma informaçăo extra sobre o elemento capítulo: neste caso, faz mais sentido o uso de um atributo.
FIG. 3.2.2.a) Exemplo 3
|
|
|
4. |
O PROJETO
|
|
|
4.1 |
Uma proposta |
|
|
|
Importaçăo de dados de uma base para outra năo é trivial quando lidamos com bases totalmente distintas em sua estruturaçăo.
Nossa soluçăo propőe o uso de analisadores (parsers) e um arquivos XML.
FIG 4.1.a) Proposta para Importaçăo de Dados
Nosso documento XML descreve um ITEM DE ACERVO da Biblioteca do IME: de que forma as informaçőes sobre um item do Acervo estăo estruturadas? Năo se trata, aqui, de saber quais as relaçőes da base de dados. Antes, é a descriçăo de um ITEM DE ACERVO a partir de seus elementos (autores, assuntos relacionados, eventos associados, ediçőes, etc), respeitando a hierarquia de registros.
|
|
|
4.2 |
Etapas do processo |
|
|
|
Definido o documento XML modelo, o processo todo envolve, basicamente, duas etapas:
| Etapa 1 |
Gerar documentos XML (segundo o modelo definido) a partir da base-origem.
|
|
|
A funçăo do parser A é gerar, usando dados de uma base-origem, um arquivo .xml para cada item de acervo a ser registrado na base nova. Importante salientar que, para cada base-origem, é necessário um parser distinto.
|
| Etapa 2 |
Fazer a carga da nova base de dados a partir dos arquivos .xml gerados.
|
|
|
A funçăo do parser B é fazer a carga da nova base de dados a partir da análise dos arquivos .xml gerados na etapa 1. |
|
|
| 5. |
Desenvolvimento |
|
|
5.1 |
Modelo XML |
|
|
|
Nosso documento XML é um arquivo.xml, contendo a estrutura de um ITEM DE ACERVO da Biblioteca do IME, juntamente com a Definiçăo do Tipo de Documento (DTD - Document Type Definition).
O DTD é descriçăo estrutural do documento e inclui regras de interpretaçăo para cada uma das informaçőes contidas no mesmo.
Ele contém a definiçăo dos elementos e listas de atributos, a cardinalidade dos elementos, a hierarquia dos registros.
Por exemplo: ITEM DE ACERVO pode ser PERIÓDICO, NĂO-PERIÓDICO, MULTIMIDIA ou TESE. Cada um deles é um elemento distinto. Determinamos, também pelo DTD, que o item pode ter mais de um ASSUNTO associado, mas apenas uma EDITORA.
Suponha que o parser A gere um arquivo itemYYY.xml a partir de dados selecionados numa das bases-origem. Esse arquivo será um documento XML válido apenas se obedecer ŕs definiçőes DTD.
A metodologia utilizada foi:
analisar os vários modelos conceituais e lógicos propostos anteriormente para a criaçăo de uma base de dados para a biblioteca;
estudar o modelo na nova base de dados;
compreender o processo de catalogaçăo de um item no acervo da Biblioteca;
estudar XML;
definir um modelo.
|
|
|
5.2 |
Parser A |
|
|
|
Para criar o parser A, é necessário ter acesso ŕ base-origem: saber como extrair, das relaçőes dessa base, os dados necessários para gerar arquivos xml válidos.
No caso específico do parser A para a base do IDBIME, utilizamos a seguinte metodologia:
criar um banco de dados no servidor Postgresql (o mesmo da nova base) com as mesmas relaçőes da base do IDBIME (script desenvolvido por Celina Maki Takemura);
copiar os dados da base IDBIME (Clipper) para o servidor Postgresql (a cópia foi feita para facilitar consultas ŕ base);
engenharia reversa para compreender as várias relaçőes da base (devido ŕ falta de documentaçăo sobre a base-origem).
criar um script para gerar arquivos xml (seguindo nosso modelo definido anteriormente) a partir da base-origem.
Esse último script - o parser A para o IDBME - foi desenvolvido em Java e requer driver para acesso ao servidor postgresql (note que a base-origem, neste momento, é uma cópia da base original do IDBME).
|
|
|
5.3 |
Parser B |
|
|
|
O desenvolvimento do parser B exige compreensăo total da base-destino (a nova base): em que ordem inserir os novos registros?É importante manter a consistęncia dos dados: ao inserir o livro "Sistemas de Bancos de Dados", preciso associá-lo ao assunto "Bancos de dados". Esse assunto já foi inserido?
A metodologia utilizada foi:
estudo do nova base e suas alteraçőes (verificar chaves primárias e estrangeiras, cardinalidade);
pesquisa por ferramentas Java para parsers XML;
estudo do SAX(Simple API for XML), uma API em Java para XML [org.xml.sax];
estudo do Apache XML Project, para utilizaçăo do pacote org.apache.xerces contendo parsers XML em Java
desenvolvimento do script - parser B - para analisar os arquivos .xml gerados e fazer a carga da nova base de dados.
Esta apresentaçăo [.pdf] mostra como foi desenvolvido um leitor de arquivos XML (uma classe em Java) que, após analisar seu (do arquivo) contéudo, faz a carga da nova base de dados com as informaçőes obtidas pelo parser.
|
|
| 6. |
Cronograma |
|
|
6.1 |
Atividades realizadas |
|
|
|
| MARÇO / 2004 |
|
| 1. | Primeiro contato com o projeto: conhecer o que já foi realizado e o que está sendo desenvolvido. |
| ABRIL / 2004 |
|
| 2. | Estudo dos modelos conceitual, lógico e físico da nova base de dados. |
| 3. | Análise de dados do ID-BIME (sistema da Biblioteca a ser substituído). Entender os tipos de dados contidos na base de dados do ID-BIME. |
| MAIO / 2004 |
|
| 4. | Análise de dados do ID-BIME. Extrair do ID-BIME o que está relacionado ao Acervo da Biblioteca. Identificar semelhanças e diferenças com o novo modelo. |
| 5. | Estudo dos módulos navegacional e operacional do novo sistema. |
| 6. | Estudo do novo modelo conceitual, apresentado pelo professor Joăo Eduardo, para a nova base de dados. |
| JUNHO / 2004 |
|
| 7. | Enumeraçăo dos atributos que faltam nas novas relaçőes. Cada integrante do grupo verifica, no modelo novo, se algo ainda năo está modelado segundo as especificaçőes de cada parte do sistema. |
| 8. | Análise do novo modelo gerado |
| JULHO / 2004 |
|
| 9. | Assimilaçăo do modelo da base de dados anterior da Biblioteca (gerar base em PostgreSQL a partir de uma base em Clipper)
Script de importaçăo dos dados para o PostgreSQL (em Perl)
|
| 10. | Estudo de ferramentas: XML e Banco de Dados |
| AGOSTO / 2004 |
|
| 12. | Desenho do novo modelo em XML |
| SETEMBRO / 2004 |
|
| 13. | Desenvolver dois parsers: um para gerar o arquivo XML com os dados do IDBIME; outro para extrair do arquivo XML os dados para a carga da base nova. |
| OUTUBRO~NOVEMBRO/ 2004 |
|
| 14. | Redefiniçăo do modelo e ajuste nos scripts dos parsers. |
| DEZEMBRO/2004 ~ FEVEREIRO/2005 |
|
| 15. | Carga da base de dados (em fase de homologaçăo) |
|
|
7. |
Ferramentas |
|
|
|
| 1. C | Script de geraçăo de uma base de dados em um servidor PostgreSQL [desenvolvido por Celina Maki Takemura] |
|
|
Compilador gcc version 3.3.3
Biblioteca "libpq-fe.h", para manipular as funçőes de acesso ao servidor PostgreSQL. Essa biblioteca é disponibilizada pelo postgresql.
|
| 2. Perl | Script de importaçăo de dados de uma base Clipper para o servidor PostgreSQL |
|
|
ActiveState Active Perl 5.6 build 638
PPM (Programmer´s Package Manager) version 2
DBD-PgPP 0.05 (Pure Perl PostgreSQL driver for the DBI)
|
| 3. XML | |
|
|
versăo 1.0
|
| 4. Java | |
|
|
Java 1.4.2
org.xml.sax
org.apache.xerces
|
| 5. Banco de Dados |
|
|
PostgreSQL 7.4.3
PgAdmin II
|
|
|
8. |
Conclusăo |
|
|
|
|
9. |
Bibliografia e Links |
|
|
|
ABITEBOUL, S.; BUNEMAN, P.; SUCIU, D. Data on the web: from relations to semistructured data and XML. California: Morgan Kauffman Publishers, 2000.
WALL, L.; CHRISTIANSEN, T.; SCHWARTZ, R.L; POTTER, S. Programming Perl. California: O´Reilly & Associates, 1996.
HOLZNER, STEVEN.Inside XML. Indiana: New Riders, 2001.
http://perl.about.com/
http://www.activestate.com
http://www.cpan.org
http://search.cpan.org/~arc (Aaron Crane)
http://crazyinsomniac.perlmonk.org/perl/ppm
PostgreSQL 7.4.3 Documentation
http://www.xml.org
Papers about XML (by Ronald Bourret)
XML Specification
Apache XML Project
|
| 1. | Tipo de Trabalho |
|
O que escolher como trabalho de formatura?
Existem, claro, as características pessoais do aluno: há quem goste de algo mais acadęmico, como Iniciaçăo Científica.
Mas gostaria de discutir outro fator determinante para a escolha de um ou outro tipo de trabalho. Como eu gosto da área de Desenvolvimento web, a idéia do Estágio Supervisionado sempre me pareceu mais interessante, pois é no estágio que temos a oportunidade de lidarmos com problemas que, muitas vezes, năo săo tratados no curso do BCC: por exemplo, o excesso de requisiçőes de um servidor web. Temos, no entanto, ironicamente, uma limitaçăo: a Internet é uma vitrine gigantesca. E a regra (para o Trabalho de Formatura) que nos obriga a disponibilizar informaçőes sobre o estágio (e, conseqüentemente, sobre o que foi desenvolvido) acaba diminuindo o leque de opçőes, embora seja compreensível que toda a documentaçăo seja necessária para validar a formatura do aluno.
Finalmente, optei por um Projeto supervisionado porque oferece a possibilidade de se desenvolver algo com embasamento teórico bastante sólido: poder estudar um assunto e aplicá-lo, observando o resultado na prática. Era um desafio trabalhar ao lado de excelentes pesquisadores da área, numa equipe com alunos também da pós-graduaçăo.
Neste projeto da Biblioteca, tive contato com ferramentas que năo săo usadas comumente nas disciplinas da graduaçăo: quando săo, năo há o intuito de se estudar a ferramenta em si ( o que, de certa forma, é aceitável, já que o dinamismo da área torna uma ferramenta obsoleta em muito pouco tempo). |
| 2. | Proposta |
|
No início, tive dificuldade em entender por que era preciso criar um modelo XML: năo seria mais rápido simplesmente fazer a carga do sistema usando apenas um parser?
Com o tempo, no entanto, analisando a complexidade do projeto do banco de dados, e tendo em vista que havia mais de uma base-origem, comecei a acreditar que a proposta do uso do XML era eficiente, mas talvez năo interessante: os scripts dos parsers seriam executados apenas uma vez, já que, após a importaçăo dos dados, os novos registros săo feitos pelo novo sistema.
Năo era uma relaçăo custo/benefíco atraente.
Até entăo, eu năo sabia que já existem muito parsers XML integrados ao java. Isso facilitou muito o desenvolvimento.
Além disso, conexăo com bancos de dados, ainda que o script esteja sendo executado localmente, trazem um custo adicional de tempo e eficięncia.
Numa base com quase 100 tabelas e mais de 100 mil registros, a execuçăo de um script que se conecte ŕ base-origem E ŕ base-destino é bastante custosa.
Separar o processo de importaçăo em etapas e utilizar um modelo XML, enfim, mostrou-se uma soluçăo bastante eficiente.
Năo há necessidade de alteraçăo no parser B (salvo possíveis alteraçőes no modelo da base de dados nova). Surgindo uma outra base-origem, a importaçăo dos dados
resume-se a criar o parser A seguindo o modelo do arquivo XML definido, deixando de lado a complexidade do modelo da base nova.
Há, também, a facilidade de se escolher a linguagem mais adequada para conexăo cada base:
no desenvolvimento deste projeto, por exemplo, a opçăo do Perl para acessar a base-origem em Clipper foi feita pois era inviável desennvolver o script em Java.
E, como os arquivos XML săo, na prática, textos puros, é muito fácil manipulá-los, seja qual for a linguagem de programaçăo.
|
| 3. | Desenvolvimento |
|
Escolha das ferramentas:
No início do projeto, optou-se por criar um script em Perl para copiar os dados da base em Clipper para a base PostgreSQL. No entanto, encontrar um módulo (perl) para a conexăo com o banco PostgreSQL acabou muito mais tempo do que eu esperava.
Colaboraçăo externa:
Năo posso deixar de citar que tive a ajuda de muitas pessoas que năo faziam parte do grupo de trabalho. Em especial, desenvolvedores de Software Livre do mundo todo. A partir de listas de discussőes e fóruns na Internet, tive a oportunidade de entrar em contato com muitas pessoas. No mundo corporativo das grandes empresas, é muito raro encontramos tantas pessoas dispostas a ajudar. O fato de ser um trabalho voltado para a Universidade facilitou o contato e a colaboraçăo.
|
| 4. | Disciplinas |
|
Das discplinas cursadas durante a graduaçăo, as que considerei mais importantes para minha formaçăo foram:
Obrigatórias
Laboratório de Programaçăo I e II
Proporcionam um primeiro contato com projetos envolvendo várias fases. Como năo há, de antemăo, uma especificaçăo clara do que é o projeto como um todo, ao longo do desenvolvimento foram necessárias várias alteraçőes nas várias fases já entregues.
Mas foi importante participar da discussăo, em sala, do que seria o projeto: como desenvolver uma parte de forma a ser utilizada por outro bloco do projeto, que estruturas de dados săo mais adequadas, etc.
Estruturas de Dados
É matéria essencial para entender como armazenar dados de forma sistemática. No uso do XML, claramente podemos perceber uma estrutura de árvore.
Engenharia de Software
A importância dessa disciplina é muito clara: basta pensar nos obstáculos citados para Laboratórios de Programaçăo
Sistemas de Bancos de Dados
Optativas Eletivas
Procurei as disciplinas que envolvessem as seguintes áreas: Engenharia de Dados, Bancos de Dados e Desenvolvimento de Sistemas para Web. Eram disciplinas que envolviam desenvolvimento de projetos, o que colaborou na assimilaçăo de vários conceitos teóricos.
|
| 5. | O BCC |
|
Por envolver alunos e professores do IME, năo houve muita diferença no desenvolvimento deste projeto no que diz respeito a ambiente de trabalho.
A única diferença foi năo poder discutir o trabalho com colegas que estivessem desenvolvendo um mesmo projeto. Na grande maioria das disciplinas, há sempre um fórum ou uma lista de discussăo, no qual os alunos enviam dúvidas, discutem soluçőes para resolver determinados problemas. Acho uma discussăo saudável: aprendemos muito com as várias soluçőes apresentadas pelos colegas.
Durante o tempo de graduçăo, vi alteraçőes no currículo do BCC: a meu ver, algumas boas, outras ruins.
Mas acho que há uma real preocupaçăo de se manter a qualidade do curso: as reuniőes entre corpos docente e discente do Departamento de Cięncia de Computaçăo procuram soluçőes para a manunteçăo da excelęncia do curso.
No geral, aproveitei também o fato de que, na USP, temos um leque variado de cursos livres e atividades extra-curriculares para os graduandos, pois acredito que participar de atividades năo restritas ŕ própria área de atuaçăo colaborem para uma formaçăo mais completa.
O Departamento de Cięncia da Computaçăo do IME também oferece Leitura Dramática, uma disciplina que, embora pareça estar mais ligada ŕ ECA-USP, é voltada para os alunos de Exatas e fornece ferramentas para lidar com o lado năo-lógico dos seres humanos.
Embora, em algumas disciplinas usuais (da área), sejam feitos trabalhos em grupo, a preocupaçăo é o produto final: entregar o trabalho. Em Leitura Dramática, exercitamos a comunicaçăo (verbal e năo-verbal) com os colegas: numa área em que o raciocínio lógico é tăo apurado, lidar com
o lado menos racional năo é tarefa simples. E, muitas vezes, o sucesso de um projeto depende da eficácia na comunicaçăo dos integrantes da equipe que desenvolve esse projeto.
O fato do departamento se preocupar em oferecer essa disciplina, ainda que seja optativa, mostra a preocupaçăo na ampla formaçăo de seus alunos.
|
| 6. | O Futuro |
|
Pretendo continuar na área de desenvolvimento de sistemas para web - agora com um cuidado ainda maior na modelagem do banco de dados.
|