| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Esse capítulo descreve funções para criar histrogramas. Histogramas fornecem um caminho conveniente de resumir a distribuição de um conjunto de dados. Um histograma consiste de um conjunto de caixas que contam o número de eventos dentro de uma classe fornecida de uma variável contínua x. Na GSL os bins de um histograma possuem números em ponto flutuante, de forma que eles possam ser usados para gravar ambas distribuições inteiras e não inteiras. Os bins podem usar conjuntos arbitrários de classes (bins uniformemente espaçados são o padrão). Ambos histogramas unidimensionais e bidimensionais são suportados.
Uma vez que um histograma tiver sido criado ele pode também ser convertido em uma função de distribuição de probabilidade. A biblioteca fornece rotinas eficientes para selecionar amostras aleatórias a partir de distribuições de probabilidade. Isso pode ser útil para gerar simulações baseadas em dados reais.
As funções são declaradas nos arquivos de cabeçalho ‘gsl_histogram.h’ e ‘gsl_histogram2d.h’.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Um histograma é definido pela seguinte estrutura,
size_t nEsse é o número de bins do histograma
double * rangeAs classes dos bins são armazenadas em um vetor estático de n+1 elementos apontado por range.
double * binOs contadores de cada caixa são armazenados em um vetor estático de n elementos apontados por bin. Os bins são números em ponto flutuante, de forma que você pode incrementá-los de valores não inteiros se necessário.
A classe para bin[i] vai de range[i] a
range[i+1]. Para n bins existem n+1 entradas no
vetor estático range. Cada caixa está incluída no final mais baixo e excluído
no final mais alto. Matematicamente isso significa que as caixas são definidos pela
seguinte desigualdade,
|
[ bin[0] )[ bin[1] )[ bin[2] )[ bin[3] )[ bin[4] )
---|---------|---------|---------|---------|---------|--- x
r[0] r[1] r[2] r[3] r[4] r[5]
Nessa figura os valores do vetor estático range são denotados por r. No lado esquerdo de cada caixa o colchête ‘[’ denota uma associação menor inclusiva (r <= x), e o parêntese ‘)’ do lado direito denota um uma associação maior excludente (x < r). Dessa forma quaisquer amostras que se encaixam acima do final do histograma são excluídas. Se você deseja incluir esses valores na última caixa você irá precisar adicionar uma caixa extra a seu histograma.
A estrutura gsl_histogram e suas funções associadas são definidas
no arquivo de cabeçalho ‘gsl_histogram.h’.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
As funções para alocação de memória para um histograma seguem o estilo das funções
malloc e free existentes no C padrão. Adicionalmente as funções para alocação de memória para um histograma também executam sua própria
verificação de erro. Caso não exista memória suficiente para alocar um
histograma então as funções chamam o controlador de erro (com um número de
erro GSL_ENOMEM) adicionalmente para retornar um apontador nulo.
Dessa forma se você usa o controlador de erro da biblioteca para abortar seu programa então não
é necessário verificar toda alocação de memória feita com o comando alloc.
Essa função aloca memória para um histograma com n bins, e
retorna um apontador para a mais recentemente estrutura gsl_histogram criada. Se
memória insuficiente estiver disponível um apontador nulo é retornado e o
controlador de erro é chamado com um código de erro de GSL_ENOMEM. Os
bins e as classes não são inicializadas, e devem ser preparadas usando uma das
funções de ajuste de classe abaixo com o objetivo de fazer o histograma pronto
para uso.
Essa função ajusta as classes de um já existente histograma h usando
o vetor estático range de tamanho size. Os valores dos bins do
histograma são ajustado para zero. O vetor estático range deve conter os
limites de bins desejados. As classes podem ser arbitrárias, desde que sigam a
restrição de que sejam monotonamente crescente.
O seguinte exemplo mostra como criar um histograma com bins logarítmicos com classes [1,10), [10,100) e [100,1000).
gsl_histogram * h = gsl_histogram_alloc (3);
/* bin[0] covers the range 1 <= x < 10 */
/* bin[1] covers the range 10 <= x < 100 */
/* bin[2] covers the range 100 <= x < 1000 */
double range[4] = { 1.0, 10.0, 100.0, 1000.0 };
gsl_histogram_set_ranges (h, range, 4);
Note que o tamanho do vetor estático range deve ser definido para ser um elemento maior que o número de bins. O elemento adicional é requerido para o valor mais alto da caixa final.
Essa função ajusta as classes de um já existente histograma h para abranger
a classe que vai de xmin a xmax uniformemente. Os valores das
caixas do histograma são ajustados para zero. As classes de caixa são mostradas na tabela
abaixo,
|
Essa função libera o histograma h e toda a memória associada a esse mensmo bin.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função copia o histograma src para dentro do já existente histograma dest, fazendo de dest uma cópia exata de src. Os dois histogramas devem ser de mesmo tamanho.
Essa função retorna um apontador para um mais recentemente criado histograma que é uma cópia exata do histograma src.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Existe duas formas de acessar os bins do histograma, ou especificando uma coordenada x ou usando o índice da caixa diretamente. As funções para acessar o histograma através de coordenadas x usam uma busca binária para identificar a caixa que abrange a classe apropriada.
Essa função atualiza o histograma h adicionando um (1.0) à caixa cuja classe contém a coordenada x.
Se x localiza-se em uma classe inválida do histograma então a função
retorna zero para indicar sucesso. Se x for menor que o limite
inferior do histograma então a função retorna GSL_EDOM, e
nenhum dos bins é modificado. Similarmente, se o valor de x for maior
que ou igual ao limite superior do histograma então a função
retorna GSL_EDOM, e nenhum dos bins é modificado. O menipulador de
erro não é chamado, todavia, uma vez que é muitas vezes necessário calcular
histogramas para uma pequena classe de grande conjunto de dados, ignorando os valores
fora da classe de interesse.
Essa função é similar a gsl_histogram_increment mas aumenta
o valor da caixa apropriada no histograma h de um
número em ponto flutuante weight.
Essa função retorna o conteúdo da i-ésima caixa do histograma
h. Se i localiza-se fora da classe válida de índice para o
histograma então o controlador de erro é chamado com um código de erro de
GSL_EDOM e a função retorna 0.
Essa função encontra os limites inferior e superior da classe da i-ésima
caixa do histograma h. Se o índice i for válido então os
correspondentes limites de classe são armazenados em lower e upper.
O limite inferior é inclusivo (i.e. eventos com essa coordenada são
incluídos no bin) e o limite superior é excludente (i.e. eventos com
a coordenada do limite superior são excluídos e caem na
caixa vizinha superior, se essa caixa vizinha superior existir). A função retorna 0 para
indicar sucesso. Se i encontra-se fora da classe válida de índices para
o histograma então o controlador de erro é chamado e a função retorna
um código de erro de GSL_EDOM.
Essas funções retornam os limites maior superior e o menor inferior de classe
e o número de bins do histograma h. Eles fornecem um caminho de
determinar esses valores sem acessar a estrutura
gsl_histogram diretamente.
Essa função ajusta todos os bins no histograma h para zero.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
As seguintes funções são usadas pelas rotinas de acesso e atualização para localizar a caixa que corresponde a uma dada coordenada x.
Essa função encontra e ajusta o índice i para o número da caixa que
abrange a coordenada x no histograma h. A caixa é
localizada usando uma busca binária. A busca inclui uma otimização para
histogramas com classe uniforme, e irá retornar a caixa correta
imediatamente nesse caso. Se x for encontrado na classe do
histograma então a função ajusta o índice i e retorna
GSL_SUCCESS. Se x encontra-se fora das classes válidas do
histograma então a função retorna GSL_EDOM e o menipulador
de erros é chamado.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função retorna o maior valor contido nos bins do histograma.
Essa função retorna o índice da caixa contendo o maior valor. No caso de muitas caixas possuirem o mesmo valor maior o menor índice é retornado.
Essa função retorna o menor valor contido nas caixas do histograma.
Essa função retorna o índice da caixa contendo o menor valor. No caso onde muitos bins possuem o mesmo valor menor o menor índice é retornado.
Essa função retorna a média da variável usada para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de bin são ignorados para os propósitos desse cálculo. A precisão do resultado é limitada pela lagura do bin.
Essa função retorna o desvio padrão da variável sobre a qual foi feito o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de caixa são ignorados para o propósito desse cálculo. a precisão do resultado é limitada pela lagura do bin.
Essa função retorna o somatório de todos os valores de bin. Valores negativos de bin são incluídos no somatórios.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função retorna 1 se a totalidade das classes de todos os bins individuais de dois histogramas forem idênticas, e 0 de outra forma.
Essa função adiciona os conteúdos dos bins no histograma h2 aos correspondentes bins do histograma h1, i.e. h'_1(i) = h_1(i) + h_2(i). Os dois histogramas devem ter identicas classes de bins.
Essa função subtrai os conteúdos dos bins no histograma h2 dos correspondentes bins do histograma h1, i.e. h'_1(i) = h_1(i) - h_2(i). Os dois histogramas devem ter identicas classes de bin.
Essa função multiplica os conteúdos dos bins do histograma h1 pelos conteúdos dos correspondentes bins no histograma h2, i.e. h'_1(i) = h_1(i) * h_2(i). Os dois histogramas devem ter idênticas classes de bin.
Essa função divide os conteúdos dos bins do histograma h1 pelos conteúdos dos correspondentes bins no histograma h2, i.e. h'_1(i) = h_1(i) / h_2(i). Os dois histogramas devem ter idênticas classes de bin.
Essa função multiplica os conteúdos dos bins do histograma h pela constante scale, i.e. h'_1(i) = h_1(i) * scale.
Essa função desloca os conteúdos dos bins do histograma h pela constante offset, i.e. h'_1(i) = h_1(i) + offset.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
A biblioteca fornece funções para leitura e escrita de histogramas para um arquivo como dados binários ou texto formatado.
Essa função escreve as classes e os bins do histograma h para o
fluxo stream no formato binário. O valor de retorno é 0 em caso de sucesso
e GSL_EFAILED se houver algum problema de escrita para o fluxo. Uma vez que
os dados são escritos no formato binário nativo pode não ser portável
entre diferentes arquiteturas.
Essa função lê para dentro de um histograma h o conteúdo de um fluxo aberto
stream no formato binário. O histograma h deve estar
pré-alocado com o tmanho correto uma vez que a função utiliza o número de
bins em h para determinar quantos bytes ler. O valor de retorno é
0 em caso de sucesso e GSL_EFAILED se ocorrer um problema de leitura a partir do
arquivo. Os dados são assumidos terem sido escrito no formato binário
nativo sobre a mesma arquitetura.
Essa função escreve as classes e bins do histograma h
linha por linha para o fluxo stream usando os especificadores de formato
range_format e bin_format. Esses especificadores devem ser um dos
formatos %g, %e or %f para números em ponto
flutuante. A função retorna 0 em caso de sucesso e GSL_EFAILED se
houver um problema de escrita para o arquivo. A saída do histograma é
formatado em três colunas, e as colunas são separadas por espaços,
dessa forma,
range[0] range[1] bin[0] range[1] range[2] bin[1] range[2] range[3] bin[2] .... range[n-1] range[n] bin[n-1]
Os formatos das classes são formatados usando range_format e o valor dos bins são formatados usando bin_format. Cada linha contém o limite inferior e superior da classe dos bins e o valor da caixa propriamente dita. Uma vez que o limite superior de uma caixa é o limite inferior das seguintes existe duplicidade desses valores entre linha mas isso permite que o histograma seja manipulado com ferramentas orientadas ao tratamento de linhas.
Essa função lê dados formatados a partir do fluxo stream para dentro do
histograma h. Os dados são assumidos estarem no formato de três colunas
usado por gsl_histogram_fprintf. O histograma h deve ser
pré-alocado com o comprimento correto uma vez que a função utiliza o tamanho de
h para determinar quantos números ler. A função retorna 0
em caso de sucesso e GSL_EFAILED se houve um problema de leitura a partir do
arquivo.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Um histograma feito através da contagem de algum evento pode ser tratado como uma medição de
uma distribuição de probabilidade. Permitindo para erro estatístico, a altura de
cada caixa representa a probabilidade de um evento onde o valor de
x encontra-se na classe daquela caixa. A função de distribuição
de probabilidade tem a forma unidimensional p(x)dx onde,
|
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
A função de distribuição de probabilidade para um histograma consiste de um conjunto de caixas que medem a probabilidade de um evento encontrar-se dentro de uma classe fornecida de uma variável contínua x. Uma função de distribuição de probabilidade é definida pela seguinte estrutura, que atualmente armazena a função de distribuição de probabilidade acumulada. Essa é a quantidade natural para gerar amostras via método de transformação inversa, pelo fato de existir um mapeamento um-a-um entre a distribuição de probabilidade acumulada e o intervalo [0,1]. Pode ser mostrado que tomando um número aleatório uniforme nesse intervalo e ajustando sua coordenada correspondente na distribuição acumulada obtemos amostras com a desejada distribuição de probabilidade.
size_t nEsse é o número de bins usado para aproximar a função de distribuição de probabilidade.
double * rangeAs classes dos bins são armazenadas no vetor estático de n+1 elementos apontados por range.
double * sumA probabilidade acumulada para os bins é armazenado no vetor estático de n elementos apontados por sum.
As seguintes funções permitem a você criar uma estrutura
gsl_histogram_pdf que representa essa distribuição de probabilidade e gera
amostras aleatórias a partir dessa estrutura.
Essa função aloca memória para uma distribuição de probabilidade com
n bins e retorna um apontador para uma mais recentemente inicializada
estrutura gsl_histogram_pdf. Se não tiver memória suficiente disponível um
apontador nulo é retornado e o controlador de erro é chamado com um código de
erro de GSL_ENOMEM.
Essa função inicializa a distribuição de probabilidade p com
o conteúdo do histograma h. Se qualquer dos bins de h for
negativo então o controlador de erro é chamado com um código de erro de
GSL_EDOM pelo fato de um distribuição de probabilidade não poder conter
valores negativos.
Essa função libera a função de distribuição de probabilidade p e toda a memória associada a essa função.
Essa função usa r, um número aleatório uniforme entre zero e
um, para calcular uma amostra aleatória simples a partir da distribuição de probabilidade
p. O algoritmo usado para calcular a amostra s é fornecido pela
seguinte fórmula,
|
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
O seguinte programa mostra como fazer um histograma simples de uma coluna
de dados numéricos fornecidos a partir da entrada padrão stdin. O programa recebe três
argumentos, especificando os limites superior e inferior do histograma e
o número de bins. A seguir lê números a partir de stdin, uma linha
por vez, e adiciona-os ao histograma. Quando não houver mais dados para
ler o programa mostra o histograma acumulado usando
gsl_histogram_fprintf.
#include <stdio.h>
#include <stdlib.h>
#include <gsl/gsl_histogram.h>
int
main (int argc, char **argv)
{
double a, b;
size_t n;
if (argc != 4)
{
printf ("Usage: gsl-histogram xmin xmax n\n"
"Computes a histogram of the data "
"on stdin using n bins from xmin "
"to xmax\n");
exit (0);
}
a = atof (argv[1]);
b = atof (argv[2]);
n = atoi (argv[3]);
{
double x;
gsl_histogram * h = gsl_histogram_alloc (n);
gsl_histogram_set_ranges_uniform (h, a, b);
while (fscanf (stdin, "%lg", &x) == 1)
{
gsl_histogram_increment (h, x);
}
gsl_histogram_fprintf (stdout, h, "%g", "%g");
gsl_histogram_free (h);
}
exit (0);
}
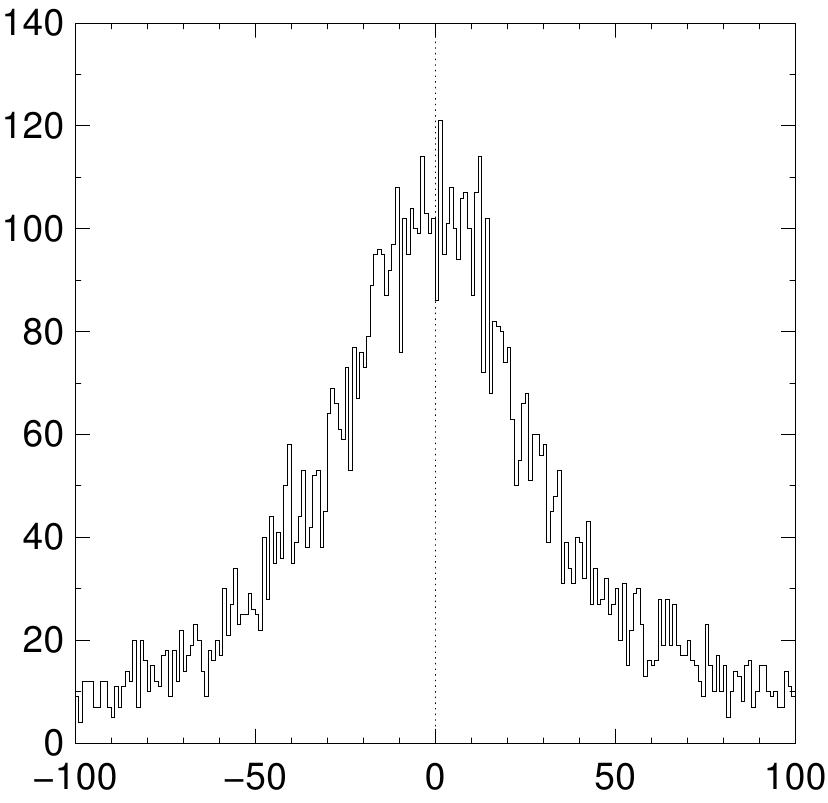
Aqui está um exemplo do programa sendo usado. Geramos 10000 amostras aleatórias de uma distribuição de Cauchy com uma largura de 30 e o histograma correspondente sobre o intervalo de -100 a 100, usando 200 bins.
$ gsl-randist 0 10000 cauchy 30 | gsl-histogram -100 100 200 > histogram.dat
Um gráfico do histograma resultante mostra a aparência familiar da distribuição de Cauchy e as flutuações causada pelo tamanho de amostra finito.
$ awk '{print $1, $3 ; print $2, $3}' histogram.dat
| graph -T X
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Um histograma bidimensional consiste em um conjunto de caixas que contam o número de eventos dentro de uma área dada do plano (x,y). O caminho mais simples de usar um histograma bidimensional é gravar informações posicionais bidimensionais, n(x,y). Outra possibilidade é formar uma distribuição conjunta gravando variáveis relacionadas. Por exemplo um detector pode gravar ambas as posições de um evento (x) e o total de energia depositada E. Dessas informações pode ser feito o histograma como a distribuição conjunta n(x,E).
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Histogramas bidimensionais são definidos pela seguinte estrutura,
size_t nx, nyEsse é o número de bins do histograma nas direções x e y.
double * xrangeAs classes dos bins na direção x são armazenados em um vetor estático de nx + 1 elementos apontados por xrange.
double * yrangeAs classes dos bins na direção y são armazenados no vetor estático de ny + 1 elementos apontados por yrange.
double * binOs contadores para cada caixa são armazenados em um vetor estático apontado por bin.
Os bins são números em ponto flutuante, de forma que você pode aumentá-los de
valores não inteiros se necessário. O vetor estático bin armazena o vetor
estático bidimensional de bins em um bloco simples de memória conforme o
mapeamento bin(i,j) = bin[i * ny + j].
A classse para bin(i,j) vai de xrange[i] a
xrange[i+1] na direção x e de yrange[j] a
yrange[j+1] na direção y. Cada caixa está incluída no limite
inferior e excluída no limite superior. Matematicamente isso significa que as
caixas são definidas pela seguinte desigualdade,
|
A estrutura gsl_histogram2d e suas funções associadas são
definidas no arquivo de cabeçalho ‘gsl_histogram2d.h’.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
As funções para alocação de memória para histograma 2D segue o estilo
de malloc e free. Adicionalmente essas funções executam sua
própria verificação de erro. Se não houver memória suficiente disponível para
alocar um histograma então as funções chamam o controlador de erro (com
um código de erro de GSL_ENOMEM) adicionalmente retornando um apontador
nulo. Dessa forma se você usa o controlador de erro da bilbioteca para abortar seu programa
então não é necessário verificar todo alloc de histograma.
Essa função aloca memória para um histograma bidimensional com
nx bins na direção x e ny bins na direção y.
A função retorna um apontador para a estrutura mais recentemente criada
gsl_histogram2d. Se não houver memória suficiente disponível um apontador nulo é retornado
e o controlador de erro é chamado com um código de erro de
GSL_ENOMEM. Os bins e classes devem ser inicializados com uma das
funções abaixo antes do histograma estar pronto para uso.
Essa função ajusta as classes do histograma existente h usando os vetores estáticos xrange e yrange de tamanho xsize e ysize respectivamente. Os valores dos bins do histograma são ajustados para zero.
Essa função ajusta as classes do histograma existente h de forma a abranger os intervalos de xmin a xmax e ymin a ymax uniformemente. Os valores dos bins do histograma são ajustados para zero.
Essa função libera o histograma 2D h e toda a memória associada a ele.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função copia o histograma src para o pré-existente histograma dest, fazendo de dest um a cópia exata de src. Os dois histogramas devem ser de mesmo tamanho.
Essa função retorna um apontador para o mais recentemente criado histograma que é uma cópia exata do histograma src.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Você pode acessar os bins de um histograma bidimensional ou especificando um par de coordenadas (x,y) ou usando os índices de caixa (i,j) diretamente. As funções para acessar o histograma através das coordenadas (x,y) usam buscas binárias nas direções x e y para identificar a caixa que abrange a classe apropriada.
Essa função atualizam o histograma h adicionando (1.0) à caixa cujas classes x e y possuem as coordenadas (x,y).
Se o ponto (x,y) localiza-se dentro das classes válidas do
histograma então a função retorna zero para indicar sucesso. Se
(x,y) encontra-se fora dos limites do histograma então a
função retorna GSL_EDOM, e nenhum dos bins é modificado. O
controlador de erro não é chamado, uma vez que é muitas vezes necessário calcular
histogramas para um pequeno intervalo de um grande conjunto de dados, ignorando quaisquer
coordenadas fora do intervalo de interesse.
Essa função é similar a gsl_histogram2d_increment mas aumenta
o valor de uma caixa apropriada no histograma h de um
número em ponto flutuante weight.
Essa função retorna o conteúdo da (i,j)-ésima caixa do
histograma h. Se (i,j) encontra-se fora do intervalo válido de
índices para o histograma então o controlador de erro é chamado com um código de
erro de GSL_EDOM e a função retorna 0.
Essas funções encontra os limites superior e inferior da classe dos bins i-ésimo
e j-ésimo nas direções x e y do histograma h.
Os limites de classe são armazenados em xlower e xupper ou em
ylower e yupper. Os limites inferiores são inclusivos
(i.e. eventos com essas coordenadas são incluídos no bin) e os
limites superiores são exclusivos (i.e. eventos com o valor do limite
superior não são incluídos e localizam-se na caixa vizinha mais alta, se essa caixa vizinho mais alto
existir). As funções retornam 0 para indicar sucesso. Se i ou
j encontram-se fora do intervalo válido de índices para o histograma então
o controlador de erro é chamado com um código de erro de GSL_EDOM.
Essas funções retornam os limites máximo superior e o mínimo inferior de intervalo
e o número de bins para as direções x e y do histograma
h. Eles fornecem um caminho de determinar esses valores sem
acessar a estrutura gsl_histogram2d diretamente.
Essa função ajusta todos os bins do histograma h para zero.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
As seguintes funções são usadas pelas rotinas de acesso e atualização para localizar a caixa que corresponde a uma dada coordenada (x,y).
Essa função encontra e ajusta os índices i e j para
a caixa que abrange as coordenadas (x,y). A caixa é
localizada usando uma busca binária. A busca inclui uma otimização para
histogramas com classes uniformes, e irá retornar a caixa correta imediatamente
nesse caso. Se (x,y) é encontrado então a função ajusta os
índices (i,j) e retorna GSL_SUCCESS. Se
(x,y) encontra-se foram do intervalo válido do histograma então a
função retorna GSL_EDOM e o controlador de erro é chamado.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função retorna o maior valor contido nos bins do histograma.
Essa função encontra os índices da caixa contendo o maior valor no histograma h e armazena o resultado em (i,j). No caso onde muitos bins possuem o mesmo maior valor o primeiro bin encontrado é retornado.
Essa função retorna o menor valor contido nos bins do histograma.
Essa função encontra os índices da caixa contendo o menor valor no histograma h e armazena o resultado em (i,j). No caso onde muitos bins possuem o mesmo valor valor máximo o primeiro bin encontrado é retornado.
Essa função retorna a média aritmética simples da variável x usada para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de bin são ignorados para os propósitos desse cálculo.
Essa função retorna a média aritmética simples da variável y usada para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de bin são ignorados para o propósito desse cálculos.
Essa função retorna o desvio padrão da variável x usada para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de caixa são ignorados para os propósitos desse cálculo.
Essa função retorna o desvio padrão da variável y usada para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de caixa são ignorados para os propósitos desse cálculo.
Essa função retorna a covariância das variáveis x e y usadas para fazer o histograma, onde o histograma é tratado como uma distribuição de probabilidade. Valores negativos de caixa são ignorados para os propósitos desse cálculo.
Essa função retorna o somatório de todos os valores de bin. Valores negativos de bin estão incluídos no somatórios.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Essa função retorna 1 se todas as classes individuais dos bins de dois histogramas forem idênticas, e 0 de outra forma.
Essa função adiciona o conteúdo dos bins no histograma h2 a bins correspondentes do histograma h1, i.e. h'_1(i,j) = h_1(i,j) + h_2(i,j). Os dois histogramas devem ter classes de bins idênticas.
Essa função subtrai o conteúdo dos bins no histograma h2 dos correspondentes bins do histograma h1, i.e. h'_1(i,j) = h_1(i,j) - h_2(i,j). Os dois histogramas devem ter classes de bins idênticas.
Essa função multiplica o conteúdo dos bins do histograma h1 pelo conteúdo dos correspondentes bins no histograma h2, i.e. h'_1(i,j) = h_1(i,j) * h_2(i,j). Os dois histogramas devem ter classes de bins idênticas.
Essa função divide o conteúdo dos bins do histograma h1 pelo conteúdo dos correspondentes bins no histograma h2, i.e. h'_1(i,j) = h_1(i,j) / h_2(i,j). Os dois histogramas devem ter classes de bins idênticas.
Essa função multiplica o conteúdo dos bins do histograma h pela constante scale, i.e. h'_1(i,j) = h_1(i,j) scale.
Essa função desloca o conteúdo dos bins do histograma h usando a constante offset, i.e. h'_1(i,j) = h_1(i,j) + offset.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
A biblioteca fornece funções para leitura e escrita de histogramas bidimensionais para um arquivo tanto como dados binários quanto como texto formatado.
Essa função escreve as classes e os bins do histograma h para o
fluxo stream no formato binário. O valor de retorno é 0 em caso de sucesso
e GSL_EFAILED se houver um problema de escrita para o arquivo. Uma vez que
os dados são escritos no formato binário nativo essa função pode não fornecer resultádos portáveis
entre diferentes arquiteturas.
Essa função coloca o resultado de uma leitura no histograma h leitura essa feita a partir do fluxo
stream em formato binário. O histograma h deve ser
pré-alocado com tamanho correto uma vez que a função usa o número de
bins x e y em h para determinar quantos bytes ler. O valor de
retorno é 0 em caso de sucesso e GSL_EFAILED se houver um problema
de leitura a partir do arquivo. Os dados são assumidos terem sido escritos no
formato binário nativo sobre a mesma arquitetura.
Essa função escreve as classes e os bins do histograma h
linha por linha para o fluxo stream usando os especificadores de formao
range_format e bin_format. Os especificadores devem ser um entre
os formatos %g, %e ou %f para números em ponto
flutuante. A função retorna 0 em caso de sucesso e GSL_EFAILED se
houver um problema de escrita para o arquivo. A saída do histograma é
formatada em cinco colunas, e as colunas são separadas por espaços,
como mostrado abaixo,
xrange[0] xrange[1] yrange[0] yrange[1] bin(0,0) xrange[0] xrange[1] yrange[1] yrange[2] bin(0,1) xrange[0] xrange[1] yrange[2] yrange[3] bin(0,2) .... xrange[0] xrange[1] yrange[ny-1] yrange[ny] bin(0,ny-1) xrange[1] xrange[2] yrange[0] yrange[1] bin(1,0) xrange[1] xrange[2] yrange[1] yrange[2] bin(1,1) xrange[1] xrange[2] yrange[1] yrange[2] bin(1,2) .... xrange[1] xrange[2] yrange[ny-1] yrange[ny] bin(1,ny-1) .... xrange[nx-1] xrange[nx] yrange[0] yrange[1] bin(nx-1,0) xrange[nx-1] xrange[nx] yrange[1] yrange[2] bin(nx-1,1) xrange[nx-1] xrange[nx] yrange[1] yrange[2] bin(nx-1,2) .... xrange[nx-1] xrange[nx] yrange[ny-1] yrange[ny] bin(nx-1,ny-1)
Cada linha contém os limites inferior e superior da caixa e o conteúdo da caixa. uma vez que os limites superiores de cada caixa são os limites inferiores da caixa vizinha existe duplicação desses valores mas isso permite que o histograma seja manipulado com ferramentas orientadas ao tratamento de linhas.
Essa função lê dados formatados a partir do fluxo stream para dentro do
histograma h. Os dados são assumidos serem no formato de cinco colunas
usado por gsl_histogram2d_fprintf. O histograma h deve ser
pré-alocado com comprimentos corretos uma vez que a função usa os tamanho
de h para determinar quantos números. A função retorna 0
em caso de sucesso e GSL_EFAILED se houver um problema de leitura a partir do
arquivo.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Da mesma forma que no caso unidimensional, um histograma bidimensional é feito através de
contagem de eventos podendo ser tratado como uam medida de uma distribuição de
probabilidade. Permitindo para erro estatístico, que a altura de cada bin
represente a probabilidade de um evento onde (x,y) encontra-se na
classe daquele bin. Para um histograma bidimensional a distribuição de
probabilidade recebe a forma p(x,y) dx dy onde,
|
size_t nx, nyEsse é o número de bins do histograma usado para aporoximar a função de distribuição de probabilidade nas direções x e y.
double * xrangeAs classes dos bins na direção x são armazenados em um vetor estático de nx + 1 elementos apontados por xrange.
double * yrangeAs classes dos bins na direção y são armazenados em um vetor estático de ny + 1 apontados por yrange.
double * sumA probabilidade acumulada para os bins é armazenada em um vetor estático de nx*ny elementos apontados por sum.
As seguintes funções permitem a você criar uma estrutura
gsl_histogram2d_pdf que representa uma distribuição de probabilidade bidimensional e
gerar amostras aleatórias a partir dessa distribuição.
Essa função aloca memória para uma distribuição de probabilidade
bidimensional de tamanho nx-by-ny e retorna um apontador a uma
estrutura gsl_histogram2d_pdf mais recentemente inicializada. Se a memória disponível
for insuficiente um apontador nulo é retornado e o controlador de erro é
chamado com um código de erro de GSL_ENOMEM.
Essa função inicializa a distribuição de probabilidade bidimensional
calculada p a partir do histograma h. Se qualquer dos bins de
h for negativo então o controlador de erro é chamado com um
código GSL_EDOM pelo fato de uma distribuição de probabilidade não pode
conter valores negativos.
Essa função libera a função de distribuição de probabilidade bidimensional p e toda a memória associada a essa função.
Essa função usa dois números aleatórios uniformes entre zero e one, r1 e r2, para calcular uma amostra aleatória simples a partir da distribuição de probabilidade bidimensional p.
| [ << ] | [ < ] | [ Acima ] | [ > ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Esse programa demonstra dois recursos dos histogramas bidimensionais. Primeiramente um histograma bidimensional de tamanho 10 por 10 é criado com x e y variando de 0 a 1. Então uns poucos pontos de amostra são adicionados ao histograma, em (0.3,0.3) com uma altura de 1, em (0.8,0.1) com a altura de 5 e em (0.7,0.9) com a altura de 0.5. Esse histograma com três eventos é usado para gerar uma amostra aleatória de 1000 eventos simulados, que são mostrados na tela.
#include <stdio.h>
#include <gsl/gsl_rng.h>
#include <gsl/gsl_histogram2d.h>
int
main (void)
{
const gsl_rng_type * T;
gsl_rng * r;
gsl_histogram2d * h = gsl_histogram2d_alloc (10, 10);
gsl_histogram2d_set_ranges_uniform (h,
0.0, 1.0,
0.0, 1.0);
gsl_histogram2d_accumulate (h, 0.3, 0.3, 1);
gsl_histogram2d_accumulate (h, 0.8, 0.1, 5);
gsl_histogram2d_accumulate (h, 0.7, 0.9, 0.5);
gsl_rng_env_setup ();
T = gsl_rng_default;
r = gsl_rng_alloc (T);
{
int i;
gsl_histogram2d_pdf * p
= gsl_histogram2d_pdf_alloc (h->nx, h->ny);
gsl_histogram2d_pdf_init (p, h);
for (i = 0; i < 1000; i++) {
double x, y;
double u = gsl_rng_uniform (r);
double v = gsl_rng_uniform (r);
gsl_histogram2d_pdf_sample (p, u, v, &x, &y);
printf ("%g %g\n", x, y);
}
gsl_histogram2d_pdf_free (p);
}
gsl_histogram2d_free (h);
gsl_rng_free (r);
return 0;
}
O seguinte gráfico mostra a distribuição de eventos simulados. Usando uma grade de alta resolução podemos ver o histograma básico original em destaque e também as flutuações estatísticas causadas pelos eventos sendo uniformemente distribuídos sobre a área dos bins originais.

| [ << ] | [ >> ] | [Topo] | [Conteúdo] | [Índice] | [ ? ] |
Esse documento foi gerado em 23 de Julho de 2013 usando texi2html 5.0.